女友同意给我更新一波设备,我要许个愿,希望我能抢到 9800x3d 和 5080~
本篇文章旨在让普通程序员也能读懂deepseekv3的模型。
更进一步,由于文章是我参照 deepseek v3 论文写出,如果需要更多信息可以直接读论文。
另外,文中图如果带有水印那么就是我水印处直接复制过来的,如果没有带水印就是我从论文中截图来的。
最后,如果有引用不周到的地方请第一时间联系我,我仅仅是抱着这个东西很酷的想法分享这篇文章。
突出点
业界认为 v3 最大的贡献就是降低了训练成本,用我看到的一句话,做到了ai平权。
但是我读过整篇论文来看,模型并没有一味的降低成本,从模型到基础建设做到了取舍,虽然我不知道每个取舍为什么这么做,但结论是成本的降低。
如果低成本只是一个结论,那么让我们先来看看 v3 的模型是如何设计的。
模型性能
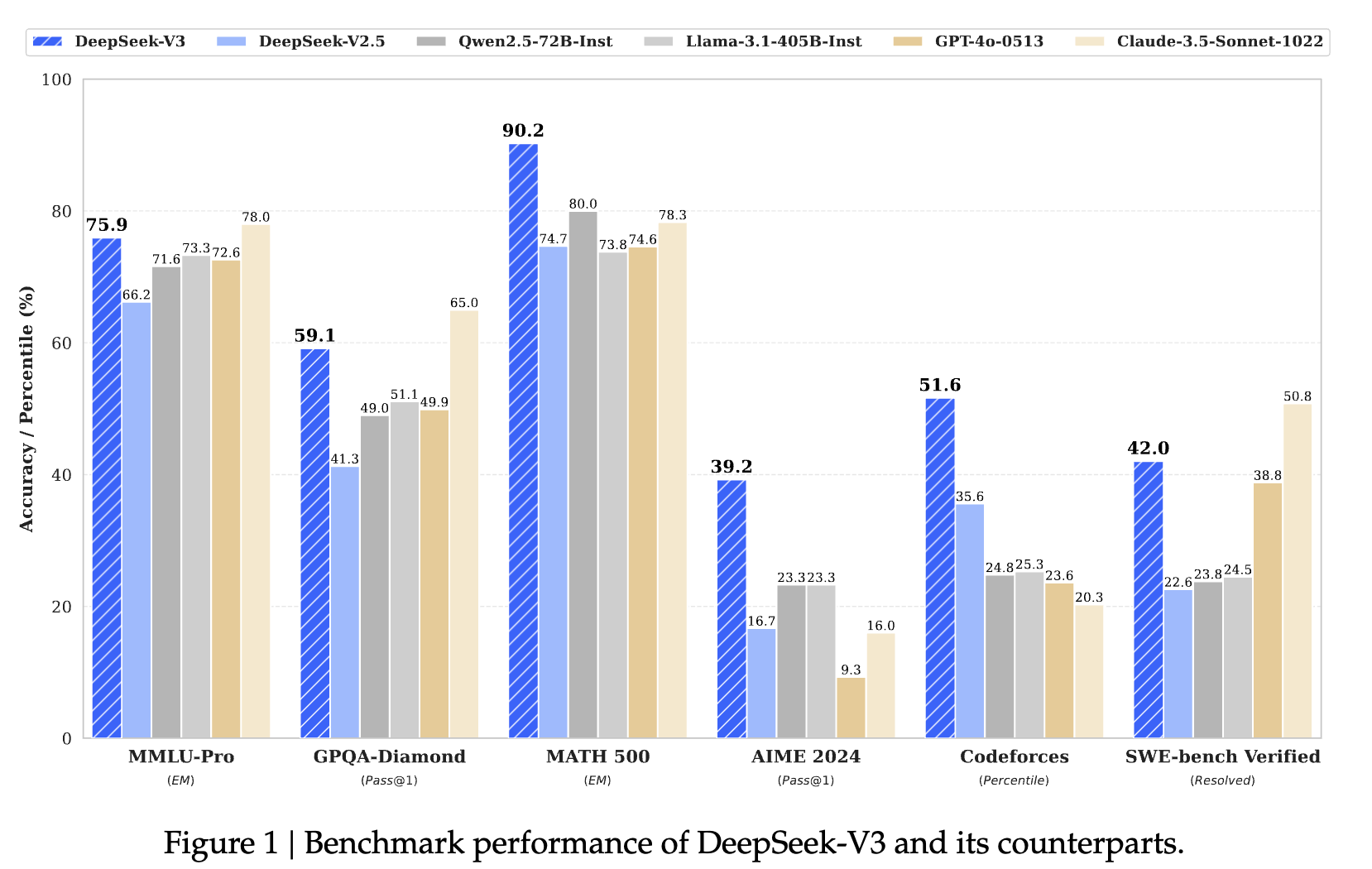
得益于 精调过的 14.8 T 数据下的 SFT 和 RL,对比其他开源模型性能都有提升。尤其在数学代码领域提升较为明显。
使用 671B 训练,并且由于 MoE系统,仅仅使用 37B 作为激活。
模型架构
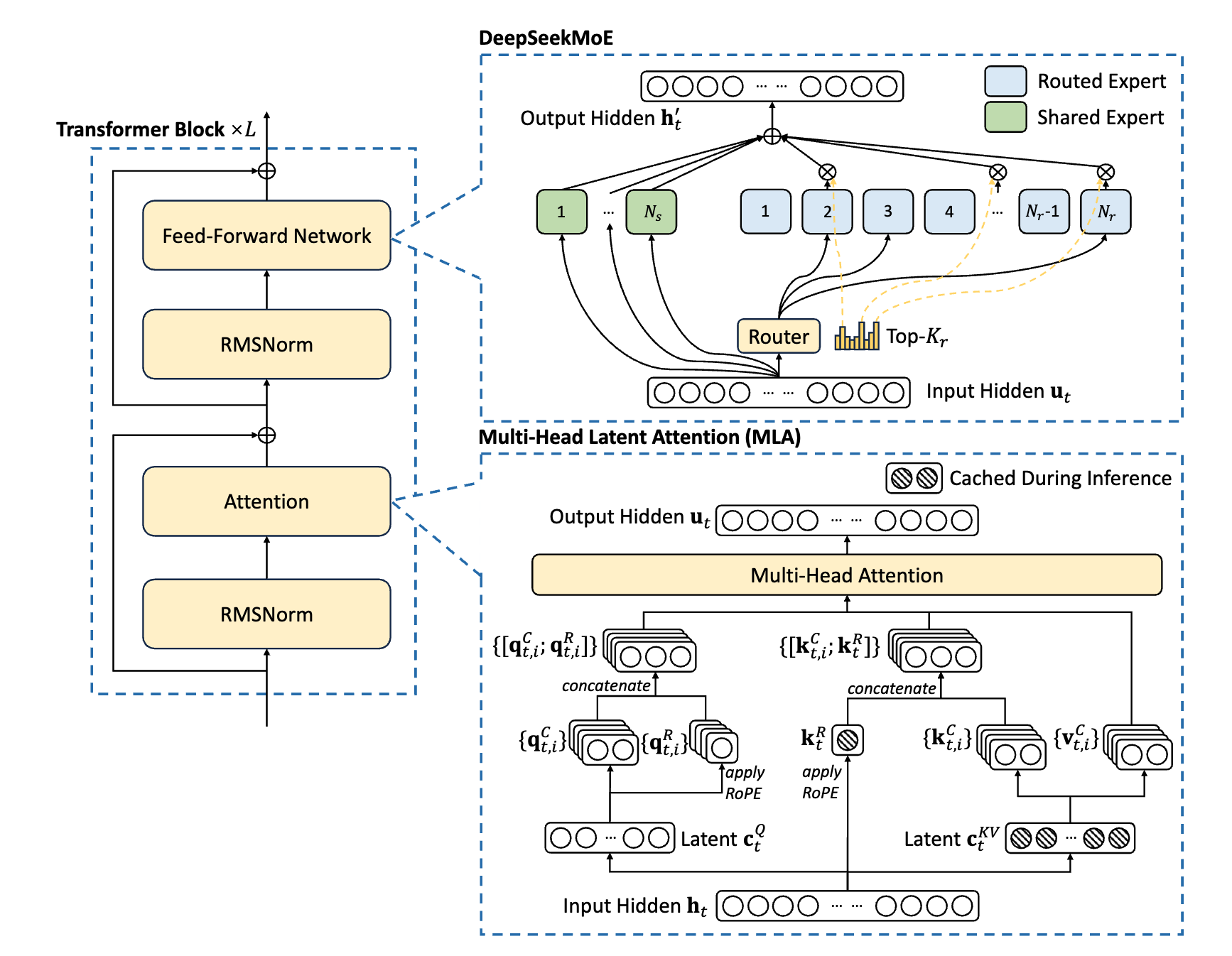
模型上创新点主要有两个,MLA和MoE,我会在下面详细介绍。同时模型还引入了 MTP 算法,用于增强模型能力,我也会在下面介绍。
Multi-Head Latent Attention
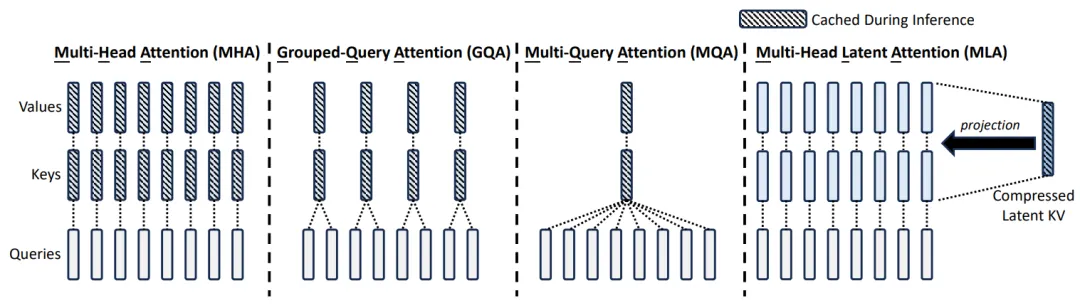
多头潜在注意力(MLA)是一种改进的注意力机制,旨在提高Transformer模型在处理长序列时的效率和性能。
在传统的Transformer架构中,多头注意力(MHA)机制允许模型同时关注输入的不同部分,每个注意力头都独立地学习输入序列中的不同特征。然而,随着序列长度的增长,键值(Key-Value,KV)缓存的大小也会线性增加,这给模型带来了显著的内存负担。为解决MHA在高计算成本和KV缓存方面的局限性,DeepSeek引入了多头潜在注意力(MLA)。
- 低秩分解(LoRA)应用于Key和Value的投影:
MLA使用低秩矩阵来近似Key和Value的投影矩阵。这意味着将一个大的投影矩阵分解为两个小矩阵的乘积。具体来说,它使用两个线性层wkv_a和wkv_b来代替一个大的Key/Value投影矩阵。wkv_a将输入投影到一个低维空间(kv_lora_rank),然后wkv_b将其投影回原始维度。这种方法显著减少了需要训练的参数数量,从而降低了内存占用和计算复杂度。 - 旋转位置编码(RoPE)应用于Query和Key:
MLA使用RoPE来为Query和Key添加位置信息。RoPE通过旋转Query和Key向量来实现,旋转的角度取决于它们在序列中的位置。这种方法不需要额外的参数,并且可以很好地泛化到不同的序列长度。 - Query的LoRA(可选):
MLA还允许对Query使用LoRA,这与Key和Value的LoRA类似,可以进一步减少参数数量。 - 优化的注意力计算(吸收式实现 ):
DeepSeek V3的MLA包含一种优化的注意力计算方式,称为“吸收式”实现。这种方法通过将部分线性变换“吸收”到注意力计算中,进一步提高了效率。具体来说,它将wkv_b的部分计算融入到注意力分数计算中,减少了后续的矩阵乘法操作。此优化减少了一次大矩阵乘法(复杂度从O(L^2d_k)降为O(L^2r)),在序列长度L较大时带来显著加速。
关键结论
- 缓存压缩:通过低秩投影,KV缓存维度从自注意力头数 * 序列长度 * k 矩阵维度 压缩至 自注意力头数 * 序列长度 * 低秩空间中保留的潜在特征维度数
- 计算加速:吸收式实现降低FLOPs约40%,尤其在大batch size场景更显著
- 精度保持:结构化参数缩减未导致性能损失,反而因正则化效应提升泛化能力
MLA通过“潜在向量”来表达信息,避免了传统注意力机制中的高维数据存储问题。利用低秩压缩技术,将多个查询向量对应到一组键值向量,实现KV缓存的有效压缩,使得DeepSeek的KV缓存减少了93.3%。
MoE with Auxiliary-Loss-Load Balancing
在模型中,使用 DeepSeekMoE 替换了基本模型中的 FFNs 层,对比传统 MoE,DeepSeek 使用更细粒度的专家,并且隔离部分专家为共享专家。

传统上,使用的 FFNs 层,需要参数量极大,所有参数都会被计算一次。
使用了 MoE 后,不同专家聚焦于不同领域的任务,在特定领域表现好。
以 v3 为例子,使用 671B 训练,并且由于 MoE系统,仅仅使用 37B 作为激活,大大降低了成本。但是 MoE 模型在通用问题上不如 FFNs 表现好。
传统上,MoE的负载均衡可能会出现路由崩溃和计算瓶颈的问题。举个例子,如果输入有 100个 token,95个分配到一个专家,剩下5个分配到5个专家。这样会导致某个专家负载很高,另外一些专家负载很低,不同专家交流跨设备也会导致设备资源利用率降低。传统的解决方案是增加辅助约束,利用超参数约束专家负载均衡;同时使用路由专家分组的方法,将相同问题发送给在同一台机器上的分组。在一些极端的模型中,可能会为了负载不高主动丢弃远端token,也影响了信息的传递。
模型用两个点来改善传统 MoE
- 使用更细的专家,由于每个专家变小,不同知识可以被更精确的化为不同专家中学习,同时得益于路由的均衡,不需要考虑负载不均衡的问题。结果就是能够显著提高专家整体的灵活性。
- 共享专家隔离策略,从众多的专家中隔离一部分作为共享专家,无论模块如何划分共享专家都会拿到所有的token计算,这样就能提升传统MoE中通用能力不足的问题。
模型增加了一个可以动态调节的bias改善路由问题
- 将 bias 其添加到选择专家的分数中来确定 top-k 路由。在训练过程中,根据专家的不同负载情况可以动态调整这个参数,防止不均衡。
- 增加节点路由限制机制,使每个token最多路由到 M 个节点,减少跨节点通信。同时结合无token丢弃策略,只使用路由保证token的信息。
Multi-Token Prediction

传统语言模型(如GPT)采用Next-Token Prediction(下一个令牌预测),通过交叉熵损失函数逐Token预测,每次预测下一个token。
在 v3 中大道至简,就是一次预测多个 token,这样做的好处是每个token的信息变得更多了,流向也更广了。同时 v3 还创新了MTP交叉熵损失计算方案,匹配这套算法。
结论
deepseek v3 模型上的新点基本就是这些,还有一些底层架构上的创新点,比如使用 DualPipe、FP8等我还没有仔细看。
通看整个模型,deepseek 将输入的每个信息尽量利用,而训练中的又将qkv矩阵做了低秩映射。不能仅仅说他们降低了精度换取低成本
还是大显存好啊!16g跑不了32b的。lol